Lecture 10: Improving Training of Neural Networks Part 2 Code
Contents
![]()
Lecture 10: Improving Training of Neural Networks Part 2 Code #
#@title
from ipywidgets import widgets
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"Q364dPTYsrk", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
display(out1)
#@title
from IPython import display as IPyDisplay
IPyDisplay.HTML(
f"""
<div>
<a href= "https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Slides/Week_4/DL4CV_Week04_Part05.pdf" target="_blank">
<img src="https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Data/Slides_Logo.png?raw=1"
alt="button link to Airtable" style="width:200px"></a>
</div>""" )
Helper functions#
Imports
import torch
import numpy as np
import matplotlib.pyplot as plt
from torch.utils.data import sampler
from torchvision import datasets
from torch.utils.data import DataLoader
from torch.utils.data import SubsetRandomSampler
from torchvision import transforms
import time
import os
import random
from distutils.version import LooseVersion as Version
Helper function for Dataloading
def get_dataloaders_mnist(batch_size, num_workers=0,
validation_fraction=None,
train_transforms=None,
test_transforms=None):
if train_transforms is None:
train_transforms = transforms.ToTensor()
if test_transforms is None:
test_transforms = transforms.ToTensor()
train_dataset = datasets.MNIST(root='data',
train=True,
transform=train_transforms,
download=True)
valid_dataset = datasets.MNIST(root='data',
train=True,
transform=test_transforms)
test_dataset = datasets.MNIST(root='data',
train=False,
transform=test_transforms)
if validation_fraction is not None:
num = int(validation_fraction * 60000)
train_indices = torch.arange(0, 60000 - num)
valid_indices = torch.arange(60000 - num, 60000)
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=batch_size,
num_workers=num_workers,
sampler=valid_sampler)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
sampler=train_sampler)
else:
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=False)
if validation_fraction is None:
return train_loader, test_loader
else:
return train_loader, valid_loader, test_loader
Helper function for evaluation
def set_all_seeds(seed):
os.environ["PL_GLOBAL_SEED"] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def set_deterministic():
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
def compute_accuracy(model, data_loader, device):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.float().to(device)
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
Helper function for training
def train_model(model, num_epochs, train_loader,
valid_loader, test_loader, optimizer, device):
start_time = time.time()
minibatch_loss_list, train_acc_list, valid_acc_list = [], [], []
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
# ## FORWARD AND BACK PROP
logits = model(features)
loss = torch.nn.functional.cross_entropy(logits, targets)
optimizer.zero_grad()
loss.backward()
# ## UPDATE MODEL PARAMETERS
optimizer.step()
# ## LOGGING
minibatch_loss_list.append(loss.item())
if not batch_idx % 50:
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Batch {batch_idx:04d}/{len(train_loader):04d} '
f'| Loss: {loss:.4f}')
model.eval()
with torch.no_grad(): # save memory during inference
train_acc = compute_accuracy(model, train_loader, device=device)
valid_acc = compute_accuracy(model, valid_loader, device=device)
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Train: {train_acc :.2f}% '
f'| Validation: {valid_acc :.2f}%')
train_acc_list.append(train_acc.item())
valid_acc_list.append(valid_acc.item())
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')
test_acc = compute_accuracy(model, test_loader, device=device)
print(f'Test accuracy {test_acc :.2f}%')
return minibatch_loss_list, train_acc_list, valid_acc_list
Helper function for Plotting
def plot_training_loss(minibatch_loss_list, num_epochs, iter_per_epoch,
results_dir=None, averaging_iterations=100):
plt.figure()
ax1 = plt.subplot(1, 1, 1)
ax1.plot(range(len(minibatch_loss_list)),
(minibatch_loss_list), label='Minibatch Loss')
if len(minibatch_loss_list) > 1000:
ax1.set_ylim([
0, np.max(minibatch_loss_list[1000:])*1.5
])
ax1.set_xlabel('Iterations')
ax1.set_ylabel('Loss')
ax1.plot(np.convolve(minibatch_loss_list,
np.ones(averaging_iterations,)/averaging_iterations,
mode='valid'),
label='Running Average')
ax1.legend()
###################
# Set scond x-axis
ax2 = ax1.twiny()
newlabel = list(range(num_epochs+1))
newpos = [e*iter_per_epoch for e in newlabel]
ax2.set_xticks(newpos[::10])
ax2.set_xticklabels(newlabel[::10])
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 45))
ax2.set_xlabel('Epochs')
ax2.set_xlim(ax1.get_xlim())
###################
plt.tight_layout()
if results_dir is not None:
image_path = os.path.join(results_dir, 'plot_training_loss.pdf')
plt.savefig(image_path)
def plot_accuracy(train_acc_list, valid_acc_list, results_dir):
num_epochs = len(train_acc_list)
plt.plot(np.arange(1, num_epochs+1),
train_acc_list, label='Training')
plt.plot(np.arange(1, num_epochs+1),
valid_acc_list, label='Validation')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
if results_dir is not None:
image_path = os.path.join(
results_dir, 'plot_acc_training_validation.pdf')
plt.savefig(image_path)
def show_examples(model, data_loader):
for batch_idx, (features, targets) in enumerate(data_loader):
with torch.no_grad():
features = features
targets = targets
logits = model(features)
predictions = torch.argmax(logits, dim=1)
break
fig, axes = plt.subplots(nrows=3, ncols=5,
sharex=True, sharey=True)
nhwc_img = np.transpose(features, axes=(0, 2, 3, 1))
nhw_img = np.squeeze(nhwc_img.numpy(), axis=3)
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhw_img[idx], cmap='binary')
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
plt.tight_layout()
plt.show()
Weight Initialization and BatchNorm#
Settings and Dataset
##########################
### SETTINGS
##########################
RANDOM_SEED = 123
BATCH_SIZE = 256
NUM_HIDDEN_1 = 50
NUM_HIDDEN_2 = 25
NUM_EPOCHS = 5
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
set_all_seeds(RANDOM_SEED)
set_deterministic()
##########################
### MNIST DATASET
##########################
train_loader, valid_loader, test_loader = get_dataloaders_mnist(
batch_size=BATCH_SIZE,
validation_fraction=0.1)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-images-idx3-ubyte.gz to data/MNIST/raw/train-images-idx3-ubyte.gz
Extracting data/MNIST/raw/train-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/train-labels-idx1-ubyte.gz to data/MNIST/raw/train-labels-idx1-ubyte.gz
Extracting data/MNIST/raw/train-labels-idx1-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-images-idx3-ubyte.gz to data/MNIST/raw/t10k-images-idx3-ubyte.gz
Extracting data/MNIST/raw/t10k-images-idx3-ubyte.gz to data/MNIST/raw
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz
Downloading http://yann.lecun.com/exdb/mnist/t10k-labels-idx1-ubyte.gz to data/MNIST/raw/t10k-labels-idx1-ubyte.gz
Extracting data/MNIST/raw/t10k-labels-idx1-ubyte.gz to data/MNIST/raw
Image batch dimensions: torch.Size([256, 1, 28, 28])
Image label dimensions: torch.Size([256])
Class labels of 10 examples: tensor([4, 5, 8, 9, 9, 4, 9, 9, 3, 9])
class MultilayerPerceptron(torch.nn.Module):
def __init__(self, num_features, num_classes, drop_proba,
num_hidden_1, num_hidden_2):
super().__init__()
self.my_network = torch.nn.Sequential(
# 1st hidden layer
torch.nn.Flatten(),
torch.nn.Linear(num_features, num_hidden_1, bias=False),
torch.nn.BatchNorm1d(num_hidden_1),
torch.nn.ReLU(),
# 2nd hidden layer
torch.nn.Linear(num_hidden_1, num_hidden_2, bias=False),
torch.nn.BatchNorm1d(num_hidden_2),
torch.nn.ReLU(),
# output layer
torch.nn.Linear(num_hidden_2, num_classes)
)
for m in self.modules():
if isinstance(m, torch.nn.Linear):
torch.nn.init.kaiming_uniform_(m.weight, mode='fan_in', nonlinearity='relu')
if m.bias is not None:
m.bias.detach().zero_()
def forward(self, x):
logits = self.my_network(x)
return logits
torch.manual_seed(RANDOM_SEED)
model = MultilayerPerceptron(num_features=28*28,
num_hidden_1=NUM_HIDDEN_1,
num_hidden_2=NUM_HIDDEN_2,
drop_proba=0.5,
num_classes=10)
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), lr=0.1)
minibatch_loss_list, train_acc_list, valid_acc_list = train_model(
model=model,
num_epochs=NUM_EPOCHS,
train_loader=train_loader,
valid_loader=valid_loader,
test_loader=test_loader,
optimizer=optimizer,
device=DEVICE)
plot_training_loss(minibatch_loss_list=minibatch_loss_list,
num_epochs=NUM_EPOCHS,
iter_per_epoch=len(train_loader),
results_dir=None,
averaging_iterations=20)
plt.show()
plot_accuracy(train_acc_list=train_acc_list,
valid_acc_list=valid_acc_list,
results_dir=None)
plt.ylim([80, 100])
plt.show()
Epoch: 001/005 | Batch 0000/0210 | Loss: 2.7446
Epoch: 001/005 | Batch 0050/0210 | Loss: 0.5098
Epoch: 001/005 | Batch 0100/0210 | Loss: 0.4496
Epoch: 001/005 | Batch 0150/0210 | Loss: 0.2792
Epoch: 001/005 | Batch 0200/0210 | Loss: 0.2946
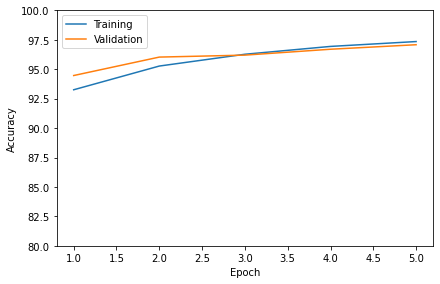
Epoch: 001/005 | Train: 93.26% | Validation: 94.47%
Time elapsed: 0.19 min
Epoch: 002/005 | Batch 0000/0210 | Loss: 0.2280
Epoch: 002/005 | Batch 0050/0210 | Loss: 0.1755
Epoch: 002/005 | Batch 0100/0210 | Loss: 0.2529
Epoch: 002/005 | Batch 0150/0210 | Loss: 0.1763
Epoch: 002/005 | Batch 0200/0210 | Loss: 0.1770
Epoch: 002/005 | Train: 95.27% | Validation: 96.03%
Time elapsed: 0.34 min
Epoch: 003/005 | Batch 0000/0210 | Loss: 0.1395
Epoch: 003/005 | Batch 0050/0210 | Loss: 0.2287
Epoch: 003/005 | Batch 0100/0210 | Loss: 0.1492
Epoch: 003/005 | Batch 0150/0210 | Loss: 0.1992
Epoch: 003/005 | Batch 0200/0210 | Loss: 0.0930
Epoch: 003/005 | Train: 96.27% | Validation: 96.20%
Time elapsed: 0.48 min
Epoch: 004/005 | Batch 0000/0210 | Loss: 0.1377
Epoch: 004/005 | Batch 0050/0210 | Loss: 0.1418
Epoch: 004/005 | Batch 0100/0210 | Loss: 0.1245
Epoch: 004/005 | Batch 0150/0210 | Loss: 0.1556
Epoch: 004/005 | Batch 0200/0210 | Loss: 0.1223
Epoch: 004/005 | Train: 96.94% | Validation: 96.70%
Time elapsed: 0.63 min
Epoch: 005/005 | Batch 0000/0210 | Loss: 0.1190
Epoch: 005/005 | Batch 0050/0210 | Loss: 0.1259
Epoch: 005/005 | Batch 0100/0210 | Loss: 0.0890
Epoch: 005/005 | Batch 0150/0210 | Loss: 0.0992
Epoch: 005/005 | Batch 0200/0210 | Loss: 0.1337
Epoch: 005/005 | Train: 97.35% | Validation: 97.08%
Time elapsed: 0.77 min
Total Training Time: 0.77 min
Test accuracy 96.16%

Acknowledgements
Code adopted from the excellent lectures of Sebastian Raschka