Lecture 3: LSTMs and GRUs Code
![]()
Lecture 3: LSTMs and GRUs Code #
#@title
from ipywidgets import widgets
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"4vryB1QhBNc", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
display(out1)
#@title
from IPython import display as IPyDisplay
IPyDisplay.HTML(
f"""
<div>
<a href= "https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Slides/Week_8/DL4CV_Week08_Part03.pdf" target="_blank">
<img src="https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Data/Slides_Logo.png?raw=1"
alt="button link to Airtable" style="width:200px"></a>
</div>""" )
import os
import time
import numpy as np
import pandas as pd
import matplotlib.pyplot as plt
import torch
import torch.nn as nn
from torch.utils.data import TensorDataset, DataLoader
from tqdm import tqdm_notebook
from sklearn.preprocessing import MinMaxScaler
# Define data root directory
data_dir = "https://raw.githubusercontent.com/gabrielloye/GRU_Prediction/master/data/"
# Visualise how our data looks
pd.read_csv(data_dir + 'AEP_hourly.csv').head()
| Datetime | AEP_MW | |
|---|---|---|
| 0 | 2004-12-31 01:00:00 | 13478.0 |
| 1 | 2004-12-31 02:00:00 | 12865.0 |
| 2 | 2004-12-31 03:00:00 | 12577.0 |
| 3 | 2004-12-31 04:00:00 | 12517.0 |
| 4 | 2004-12-31 05:00:00 | 12670.0 |
# The scaler objects will be stored in this dictionary so that our output test data from the model can be re-scaled during evaluation
label_scalers = {}
train_x = []
test_x = {}
test_y = {}
dir_list = ['COMED_hourly.csv','DAYTON_hourly.csv','DEOK_hourly.csv','DOM_hourly.csv','DUQ_hourly.csv',
'EKPC_hourly.csv','FE_hourly.csv','NI_hourly.csv','PJME_hourly.csv','PJMW_hourly.csv',
'PJM_Load_hourly.csv','pjm_hourly_est.csv']
for file in dir_list:
# Skipping the files we're not using
if file[-4:] != ".csv" or file == "pjm_hourly_est.csv":
continue
# Store csv file in a Pandas DataFrame
df = pd.read_csv('{}/{}'.format(data_dir, file), parse_dates=[0])
# Processing the time data into suitable input formats
df['hour'] = df.apply(lambda x: x['Datetime'].hour,axis=1)
df['dayofweek'] = df.apply(lambda x: x['Datetime'].dayofweek,axis=1)
df['month'] = df.apply(lambda x: x['Datetime'].month,axis=1)
df['dayofyear'] = df.apply(lambda x: x['Datetime'].dayofyear,axis=1)
df = df.sort_values("Datetime").drop("Datetime",axis=1)
# Scaling the input data
sc = MinMaxScaler()
label_sc = MinMaxScaler()
data = sc.fit_transform(df.values)
# Obtaining the Scale for the labels(usage data) so that output can be re-scaled to actual value during evaluation
label_sc.fit(df.iloc[:,0].values.reshape(-1,1))
label_scalers[file] = label_sc
# Define lookback period and split inputs/labels
lookback = 90
inputs = np.zeros((len(data)-lookback,lookback,df.shape[1]))
labels = np.zeros(len(data)-lookback)
for i in range(lookback, len(data)):
inputs[i-lookback] = data[i-lookback:i]
labels[i-lookback] = data[i,0]
inputs = inputs.reshape(-1,lookback,df.shape[1])
labels = labels.reshape(-1,1)
# Split data into train/test portions and combining all data from different files into a single array
test_portion = int(0.1*len(inputs))
if len(train_x) == 0:
train_x = inputs[:-test_portion]
train_y = labels[:-test_portion]
else:
train_x = np.concatenate((train_x,inputs[:-test_portion]))
train_y = np.concatenate((train_y,labels[:-test_portion]))
test_x[file] = (inputs[-test_portion:])
test_y[file] = (labels[-test_portion:])
batch_size = 1024
train_data = TensorDataset(torch.from_numpy(train_x), torch.from_numpy(train_y))
train_loader = DataLoader(train_data, shuffle=True, batch_size=batch_size, drop_last=True)
# torch.cuda.is_available() checks and returns a Boolean True if a GPU is available, else it'll return False
is_cuda = torch.cuda.is_available()
# If we have a GPU available, we'll set our device to GPU. We'll use this device variable later in our code.
if is_cuda:
device = torch.device("cuda")
else:
device = torch.device("cpu")
class GRUNet(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, n_layers, drop_prob=0.2):
super(GRUNet, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.gru = nn.GRU(input_dim, hidden_dim, n_layers, batch_first=True, dropout=drop_prob)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x, h):
out, h = self.gru(x, h)
out = self.fc(self.relu(out[:,-1]))
return out, h
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device)
return hidden
class LSTMNet(nn.Module):
def __init__(self, input_dim, hidden_dim, output_dim, n_layers, drop_prob=0.2):
super(LSTMNet, self).__init__()
self.hidden_dim = hidden_dim
self.n_layers = n_layers
self.lstm = nn.LSTM(input_dim, hidden_dim, n_layers, batch_first=True, dropout=drop_prob)
self.fc = nn.Linear(hidden_dim, output_dim)
self.relu = nn.ReLU()
def forward(self, x, h):
out, h = self.lstm(x, h)
out = self.fc(self.relu(out[:,-1]))
return out, h
def init_hidden(self, batch_size):
weight = next(self.parameters()).data
hidden = (weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device),
weight.new(self.n_layers, batch_size, self.hidden_dim).zero_().to(device))
return hidden
def train(train_loader, learn_rate, hidden_dim=256, EPOCHS=3, model_type="GRU"):
# Setting common hyperparameters
input_dim = next(iter(train_loader))[0].shape[2]
output_dim = 1
n_layers = 2
# Instantiating the models
if model_type == "GRU":
model = GRUNet(input_dim, hidden_dim, output_dim, n_layers)
else:
model = LSTMNet(input_dim, hidden_dim, output_dim, n_layers)
model.to(device)
# Defining loss function and optimizer
criterion = nn.MSELoss()
optimizer = torch.optim.Adam(model.parameters(), lr=learn_rate)
model.train()
print("Starting Training of {} model".format(model_type))
epoch_times = []
# Start training loop
for epoch in range(1,EPOCHS+1):
start_time = time.clock()
h = model.init_hidden(batch_size)
avg_loss = 0.
counter = 0
for x, label in train_loader:
counter += 1
if model_type == "GRU":
h = h.data
else:
h = tuple([e.data for e in h])
model.zero_grad()
out, h = model(x.to(device).float(), h)
loss = criterion(out, label.to(device).float())
loss.backward()
optimizer.step()
avg_loss += loss.item()
if counter%200 == 0:
print("Epoch {}......Step: {}/{}....... Average Loss for Epoch: {}".format(epoch, counter, len(train_loader), avg_loss/counter))
current_time = time.clock()
print("Epoch {}/{} Done, Total Loss: {}".format(epoch, EPOCHS, avg_loss/len(train_loader)))
print("Total Time Elapsed: {} seconds".format(str(current_time-start_time)))
epoch_times.append(current_time-start_time)
print("Total Training Time: {} seconds".format(str(sum(epoch_times))))
return model
def evaluate(model, test_x, test_y, label_scalers):
model.eval()
outputs = []
targets = []
start_time = time.clock()
for i in test_x.keys():
inp = torch.from_numpy(np.array(test_x[i]))
labs = torch.from_numpy(np.array(test_y[i]))
h = model.init_hidden(inp.shape[0])
out, h = model(inp.to(device).float(), h)
outputs.append(label_scalers[i].inverse_transform(out.cpu().detach().numpy()).reshape(-1))
targets.append(label_scalers[i].inverse_transform(labs.numpy()).reshape(-1))
print("Evaluation Time: {}".format(str(time.clock()-start_time)))
sMAPE = 0
for i in range(len(outputs)):
sMAPE += np.mean(abs(outputs[i]-targets[i])/(targets[i]+outputs[i])/2)/len(outputs)
print("sMAPE: {}%".format(sMAPE*100))
return outputs, targets, sMAPE
lr = 0.001
gru_model = train(train_loader, lr, model_type="GRU")
Lstm_model = train(train_loader, lr, model_type="LSTM")
Starting Training of GRU model
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:23: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
Epoch 1......Step: 200/850....... Average Loss for Epoch: 0.006096988379722461
Epoch 1......Step: 400/850....... Average Loss for Epoch: 0.0033717130668082973
Epoch 1......Step: 600/850....... Average Loss for Epoch: 0.0023807923902253
Epoch 1......Step: 800/850....... Average Loss for Epoch: 0.0018677535402821376
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:42: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
Epoch 1/3 Done, Total Loss: 0.0017741594380555291
Total Time Elapsed: 125.45646 seconds
Epoch 2......Step: 200/850....... Average Loss for Epoch: 0.00023937143669172656
Epoch 2......Step: 400/850....... Average Loss for Epoch: 0.00023066764828399755
Epoch 2......Step: 600/850....... Average Loss for Epoch: 0.0002169433935099126
Epoch 2......Step: 800/850....... Average Loss for Epoch: 0.0002091762806958286
Epoch 2/3 Done, Total Loss: 0.0002064857040600413
Total Time Elapsed: 130.49326200000002 seconds
Epoch 3......Step: 200/850....... Average Loss for Epoch: 0.00016747852416301612
Epoch 3......Step: 400/850....... Average Loss for Epoch: 0.00016314030850480776
Epoch 3......Step: 600/850....... Average Loss for Epoch: 0.00015525763972012405
Epoch 3......Step: 800/850....... Average Loss for Epoch: 0.00015253184241373674
Epoch 3/3 Done, Total Loss: 0.00015117165770361146
Total Time Elapsed: 131.01842499999998 seconds
Total Training Time: 386.968147 seconds
Starting Training of LSTM model
Epoch 1......Step: 200/850....... Average Loss for Epoch: 0.01742906263214536
Epoch 1......Step: 400/850....... Average Loss for Epoch: 0.009573000348755158
Epoch 1......Step: 600/850....... Average Loss for Epoch: 0.006692949180433061
Epoch 1......Step: 800/850....... Average Loss for Epoch: 0.005174602072074776
Epoch 1/3 Done, Total Loss: 0.004901739941800342
Total Time Elapsed: 157.33527200000003 seconds
Epoch 2......Step: 200/850....... Average Loss for Epoch: 0.00045957421520142816
Epoch 2......Step: 400/850....... Average Loss for Epoch: 0.00042132533373660406
Epoch 2......Step: 600/850....... Average Loss for Epoch: 0.00039139978495465283
Epoch 2......Step: 800/850....... Average Loss for Epoch: 0.0003637413315118465
Epoch 2/3 Done, Total Loss: 0.00035697229251073785
Total Time Elapsed: 157.62731499999995 seconds
Epoch 3......Step: 200/850....... Average Loss for Epoch: 0.0002447167839272879
Epoch 3......Step: 400/850....... Average Loss for Epoch: 0.00023587409501487855
Epoch 3......Step: 600/850....... Average Loss for Epoch: 0.00022476817039811673
Epoch 3......Step: 800/850....... Average Loss for Epoch: 0.00021843789189006203
Epoch 3/3 Done, Total Loss: 0.0002170798575731597
Total Time Elapsed: 157.80152699999996 seconds
Total Training Time: 472.76411399999995 seconds
gru_outputs, targets, gru_sMAPE = evaluate(gru_model, test_x, test_y, label_scalers)
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:53: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
Evaluation Time: 3.7276449999999386
sMAPE: 0.28466981483230724%
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:61: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
lstm_outputs, targets, lstm_sMAPE = evaluate(Lstm_model, test_x, test_y, label_scalers)
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:53: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
Evaluation Time: 4.873326999999904
sMAPE: 0.32362494872049735%
/usr/local/lib/python3.7/dist-packages/ipykernel_launcher.py:61: DeprecationWarning: time.clock has been deprecated in Python 3.3 and will be removed from Python 3.8: use time.perf_counter or time.process_time instead
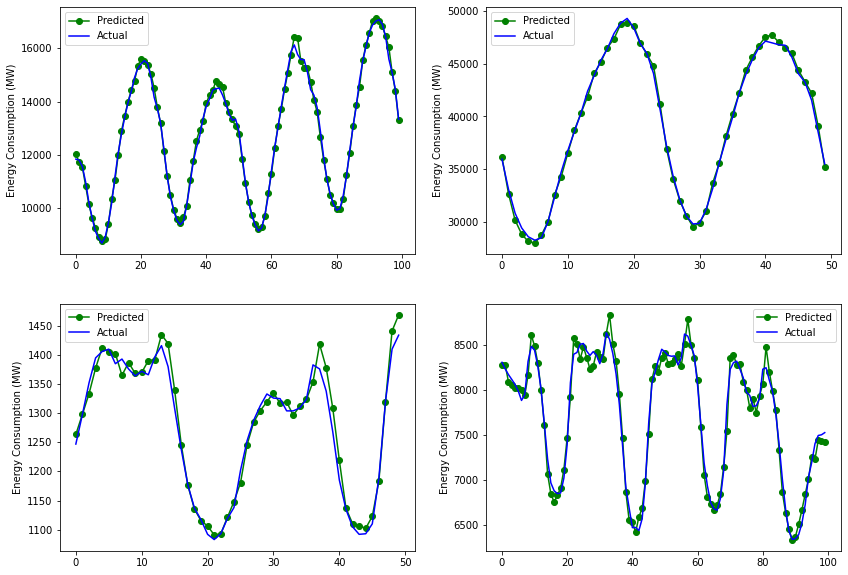
plt.figure(figsize=(14,10))
plt.subplot(2,2,1)
plt.plot(gru_outputs[0][-100:], "-o", color="g", label="Predicted")
plt.plot(targets[0][-100:], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,2)
plt.plot(gru_outputs[8][-50:], "-o", color="g", label="Predicted")
plt.plot(targets[8][-50:], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,3)
plt.plot(gru_outputs[4][:50], "-o", color="g", label="Predicted")
plt.plot(targets[4][:50], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.subplot(2,2,4)
plt.plot(lstm_outputs[6][:100], "-o", color="g", label="Predicted")
plt.plot(targets[6][:100], color="b", label="Actual")
plt.ylabel('Energy Consumption (MW)')
plt.legend()
plt.show()
Acknowledgements