Lecture 7: Finetuning in CNNs Code
Contents
![]()
Lecture 7: Finetuning in CNNs Code #
#@title
from ipywidgets import widgets
out1 = widgets.Output()
with out1:
from IPython.display import YouTubeVideo
video = YouTubeVideo(id=f"cDvkwPBOWdo", width=854, height=480, fs=1, rel=0)
print("Video available at https://youtube.com/watch?v=" + video.id)
display(video)
display(out1)
#@title
from IPython import display as IPyDisplay
IPyDisplay.HTML(
f"""
<div>
<a href= "https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Slides/Week_5/DL4CV_Week05_Part05.pdf" target="_blank">
<img src="https://github.com/DL4CV-NPTEL/Deep-Learning-For-Computer-Vision/blob/main/Data/Slides_Logo.png?raw=1"
alt="button link to Airtable" style="width:200px"></a>
</div>""" )
Imports
import torch
from torch.utils.data import sampler
import torchvision
from torchvision import datasets
from torch.utils.data import DataLoader
from torch.utils.data import SubsetRandomSampler
from torchvision import transforms
import os
import numpy as np
import random
from distutils.version import LooseVersion as Version
from itertools import product
import time
import matplotlib.pyplot as plt
Helper function for Dataloading
class UnNormalize(object):
def __init__(self, mean, std):
self.mean = mean
self.std = std
def __call__(self, tensor):
"""
Parameters:
------------
tensor (Tensor): Tensor image of size (C, H, W) to be normalized.
Returns:
------------
Tensor: Normalized image.
"""
for t, m, s in zip(tensor, self.mean, self.std):
t.mul_(s).add_(m)
return tensor
def get_dataloaders_mnist(batch_size, num_workers=0,
validation_fraction=None,
train_transforms=None,
test_transforms=None):
if train_transforms is None:
train_transforms = transforms.ToTensor()
if test_transforms is None:
test_transforms = transforms.ToTensor()
train_dataset = datasets.MNIST(root='data',
train=True,
transform=train_transforms,
download=True)
valid_dataset = datasets.MNIST(root='data',
train=True,
transform=test_transforms)
test_dataset = datasets.MNIST(root='data',
train=False,
transform=test_transforms)
if validation_fraction is not None:
num = int(validation_fraction * 60000)
train_indices = torch.arange(0, 60000 - num)
valid_indices = torch.arange(60000 - num, 60000)
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=batch_size,
num_workers=num_workers,
sampler=valid_sampler)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
sampler=train_sampler)
else:
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=False)
if validation_fraction is None:
return train_loader, test_loader
else:
return train_loader, valid_loader, test_loader
def get_dataloaders_cifar10(batch_size, num_workers=0,
validation_fraction=None,
train_transforms=None,
test_transforms=None):
if train_transforms is None:
train_transforms = transforms.ToTensor()
if test_transforms is None:
test_transforms = transforms.ToTensor()
train_dataset = datasets.CIFAR10(root='data',
train=True,
transform=train_transforms,
download=True)
valid_dataset = datasets.CIFAR10(root='data',
train=True,
transform=test_transforms)
test_dataset = datasets.CIFAR10(root='data',
train=False,
transform=test_transforms)
if validation_fraction is not None:
num = int(validation_fraction * 50000)
train_indices = torch.arange(0, 50000 - num)
valid_indices = torch.arange(50000 - num, 50000)
train_sampler = SubsetRandomSampler(train_indices)
valid_sampler = SubsetRandomSampler(valid_indices)
valid_loader = DataLoader(dataset=valid_dataset,
batch_size=batch_size,
num_workers=num_workers,
sampler=valid_sampler)
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
sampler=train_sampler)
else:
train_loader = DataLoader(dataset=train_dataset,
batch_size=batch_size,
num_workers=num_workers,
drop_last=True,
shuffle=True)
test_loader = DataLoader(dataset=test_dataset,
batch_size=batch_size,
num_workers=num_workers,
shuffle=False)
if validation_fraction is None:
return train_loader, test_loader
else:
return train_loader, valid_loader, test_loader
Helper function for evaluation
def set_all_seeds(seed):
os.environ["PL_GLOBAL_SEED"] = str(seed)
random.seed(seed)
np.random.seed(seed)
torch.manual_seed(seed)
torch.cuda.manual_seed_all(seed)
def set_deterministic(use_tensorcores=False):
if torch.cuda.is_available():
torch.backends.cudnn.benchmark = False
torch.backends.cudnn.deterministic = True
if torch.__version__ <= Version("1.7"):
torch.set_deterministic(True)
else:
torch.use_deterministic_algorithms(True)
# The following are set to True by default and allow cards
# like the Ampere and newer to utilize tensorcores for
# convolutions and matrix multiplications, which can result
# in a significant speed-up. However, results may differ compared
# to card how don't use mixed precision via tensor cores.
torch.backends.cuda.matmul.allow_tf32 = use_tensorcores
torch.backends.cudnn.allow_tf32 = use_tensorcores
def compute_accuracy(model, data_loader, device):
with torch.no_grad():
correct_pred, num_examples = 0, 0
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets.float().to(device)
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
num_examples += targets.size(0)
correct_pred += (predicted_labels == targets).sum()
return correct_pred.float()/num_examples * 100
def compute_confusion_matrix(model, data_loader, device):
all_targets, all_predictions = [], []
with torch.no_grad():
for i, (features, targets) in enumerate(data_loader):
features = features.to(device)
targets = targets
logits = model(features)
_, predicted_labels = torch.max(logits, 1)
all_targets.extend(targets.to('cpu'))
all_predictions.extend(predicted_labels.to('cpu'))
all_predictions = all_predictions
all_predictions = np.array(all_predictions)
all_targets = np.array(all_targets)
class_labels = np.unique(np.concatenate((all_targets, all_predictions)))
if class_labels.shape[0] == 1:
if class_labels[0] != 0:
class_labels = np.array([0, class_labels[0]])
else:
class_labels = np.array([class_labels[0], 1])
n_labels = class_labels.shape[0]
lst = []
z = list(zip(all_targets, all_predictions))
for combi in product(class_labels, repeat=2):
lst.append(z.count(combi))
mat = np.asarray(lst)[:, None].reshape(n_labels, n_labels)
return mat
Helper function for training
import time
import torch
def train_model(model, num_epochs, train_loader,
valid_loader, test_loader, optimizer,
device, logging_interval=50,
scheduler=None,
scheduler_on='valid_acc'):
start_time = time.time()
minibatch_loss_list, train_acc_list, valid_acc_list = [], [], []
for epoch in range(num_epochs):
model.train()
for batch_idx, (features, targets) in enumerate(train_loader):
features = features.to(device)
targets = targets.to(device)
# ## FORWARD AND BACK PROP
logits = model(features)
loss = torch.nn.functional.cross_entropy(logits, targets)
optimizer.zero_grad()
loss.backward()
# ## UPDATE MODEL PARAMETERS
optimizer.step()
# ## LOGGING
minibatch_loss_list.append(loss.item())
if not batch_idx % logging_interval:
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Batch {batch_idx:04d}/{len(train_loader):04d} '
f'| Loss: {loss:.4f}')
model.eval()
with torch.no_grad(): # save memory during inference
train_acc = compute_accuracy(model, train_loader, device=device)
valid_acc = compute_accuracy(model, valid_loader, device=device)
print(f'Epoch: {epoch+1:03d}/{num_epochs:03d} '
f'| Train: {train_acc :.2f}% '
f'| Validation: {valid_acc :.2f}%')
train_acc_list.append(train_acc.item())
valid_acc_list.append(valid_acc.item())
elapsed = (time.time() - start_time)/60
print(f'Time elapsed: {elapsed:.2f} min')
if scheduler is not None:
if scheduler_on == 'valid_acc':
scheduler.step(valid_acc_list[-1])
elif scheduler_on == 'minibatch_loss':
scheduler.step(minibatch_loss_list[-1])
else:
raise ValueError(f'Invalid `scheduler_on` choice.')
elapsed = (time.time() - start_time)/60
print(f'Total Training Time: {elapsed:.2f} min')
test_acc = compute_accuracy(model, test_loader, device=device)
print(f'Test accuracy {test_acc :.2f}%')
return minibatch_loss_list, train_acc_list, valid_acc_list
Helper function for Plotting
def plot_training_loss(minibatch_loss_list, num_epochs, iter_per_epoch,
results_dir=None, averaging_iterations=100):
plt.figure()
ax1 = plt.subplot(1, 1, 1)
ax1.plot(range(len(minibatch_loss_list)),
(minibatch_loss_list), label='Minibatch Loss')
if len(minibatch_loss_list) > 1000:
ax1.set_ylim([
0, np.max(minibatch_loss_list[1000:])*1.5
])
ax1.set_xlabel('Iterations')
ax1.set_ylabel('Loss')
ax1.plot(np.convolve(minibatch_loss_list,
np.ones(averaging_iterations,)/averaging_iterations,
mode='valid'),
label='Running Average')
ax1.legend()
###################
# Set scond x-axis
ax2 = ax1.twiny()
newlabel = list(range(num_epochs+1))
newpos = [e*iter_per_epoch for e in newlabel]
ax2.set_xticks(newpos[::10])
ax2.set_xticklabels(newlabel[::10])
ax2.xaxis.set_ticks_position('bottom')
ax2.xaxis.set_label_position('bottom')
ax2.spines['bottom'].set_position(('outward', 45))
ax2.set_xlabel('Epochs')
ax2.set_xlim(ax1.get_xlim())
###################
plt.tight_layout()
if results_dir is not None:
image_path = os.path.join(results_dir, 'plot_training_loss.pdf')
plt.savefig(image_path)
def plot_accuracy(train_acc_list, valid_acc_list, results_dir):
num_epochs = len(train_acc_list)
plt.plot(np.arange(1, num_epochs+1),
train_acc_list, label='Training')
plt.plot(np.arange(1, num_epochs+1),
valid_acc_list, label='Validation')
plt.xlabel('Epoch')
plt.ylabel('Accuracy')
plt.legend()
plt.tight_layout()
if results_dir is not None:
image_path = os.path.join(
results_dir, 'plot_acc_training_validation.pdf')
plt.savefig(image_path)
def show_examples(model, data_loader, unnormalizer=None, class_dict=None):
for batch_idx, (features, targets) in enumerate(data_loader):
with torch.no_grad():
features = features
targets = targets
logits = model(features)
predictions = torch.argmax(logits, dim=1)
break
fig, axes = plt.subplots(nrows=3, ncols=5,
sharex=True, sharey=True)
if unnormalizer is not None:
for idx in range(features.shape[0]):
features[idx] = unnormalizer(features[idx])
nhwc_img = np.transpose(features, axes=(0, 2, 3, 1))
if nhwc_img.shape[-1] == 1:
nhw_img = np.squeeze(nhwc_img.numpy(), axis=3)
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhw_img[idx], cmap='binary')
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
else:
for idx, ax in enumerate(axes.ravel()):
ax.imshow(nhwc_img[idx])
if class_dict is not None:
ax.title.set_text(f'P: {class_dict[predictions[idx].item()]}'
f'\nT: {class_dict[targets[idx].item()]}')
else:
ax.title.set_text(f'P: {predictions[idx]} | T: {targets[idx]}')
ax.axison = False
plt.tight_layout()
plt.show()
def plot_confusion_matrix(conf_mat,
hide_spines=False,
hide_ticks=False,
figsize=None,
cmap=None,
colorbar=False,
show_absolute=True,
show_normed=False,
class_names=None):
if not (show_absolute or show_normed):
raise AssertionError('Both show_absolute and show_normed are False')
if class_names is not None and len(class_names) != len(conf_mat):
raise AssertionError('len(class_names) should be equal to number of'
'classes in the dataset')
total_samples = conf_mat.sum(axis=1)[:, np.newaxis]
normed_conf_mat = conf_mat.astype('float') / total_samples
fig, ax = plt.subplots(figsize=figsize)
ax.grid(False)
if cmap is None:
cmap = plt.cm.Blues
if figsize is None:
figsize = (len(conf_mat)*1.25, len(conf_mat)*1.25)
if show_normed:
matshow = ax.matshow(normed_conf_mat, cmap=cmap)
else:
matshow = ax.matshow(conf_mat, cmap=cmap)
if colorbar:
fig.colorbar(matshow)
for i in range(conf_mat.shape[0]):
for j in range(conf_mat.shape[1]):
cell_text = ""
if show_absolute:
cell_text += format(conf_mat[i, j], 'd')
if show_normed:
cell_text += "\n" + '('
cell_text += format(normed_conf_mat[i, j], '.2f') + ')'
else:
cell_text += format(normed_conf_mat[i, j], '.2f')
ax.text(x=j,
y=i,
s=cell_text,
va='center',
ha='center',
color="white" if normed_conf_mat[i, j] > 0.5 else "black")
if class_names is not None:
tick_marks = np.arange(len(class_names))
plt.xticks(tick_marks, class_names, rotation=90)
plt.yticks(tick_marks, class_names)
if hide_spines:
ax.spines['right'].set_visible(False)
ax.spines['top'].set_visible(False)
ax.spines['left'].set_visible(False)
ax.spines['bottom'].set_visible(False)
ax.yaxis.set_ticks_position('left')
ax.xaxis.set_ticks_position('bottom')
if hide_ticks:
ax.axes.get_yaxis().set_ticks([])
ax.axes.get_xaxis().set_ticks([])
plt.xlabel('predicted label')
plt.ylabel('true label')
return fig, ax
Transfer Learning – VGG-16 on Cifar-10#
Setting and Dataset
RANDOM_SEED = 123
BATCH_SIZE = 256
NUM_EPOCHS = 5
DEVICE = torch.device('cuda:0' if torch.cuda.is_available() else 'cpu')
set_all_seeds(RANDOM_SEED)
##########################
### CIFAR-10 DATASET
##########################
train_transforms = transforms.Compose([
transforms.Resize((70, 70)),
transforms.RandomCrop((64, 64)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.225))])
test_transforms = transforms.Compose([
transforms.Resize((70, 70)),
transforms.CenterCrop((64, 64)),
transforms.ToTensor(),
transforms.Normalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2255))])
train_loader, valid_loader, test_loader = get_dataloaders_cifar10(
batch_size=BATCH_SIZE,
validation_fraction=0.1,
train_transforms=train_transforms,
test_transforms=test_transforms,
num_workers=2)
# Checking the dataset
for images, labels in train_loader:
print('Image batch dimensions:', images.shape)
print('Image label dimensions:', labels.shape)
print('Class labels of 10 examples:', labels[:10])
break
Files already downloaded and verified
Image batch dimensions: torch.Size([256, 3, 64, 64])
Image label dimensions: torch.Size([256])
Class labels of 10 examples: tensor([4, 7, 4, 6, 2, 6, 9, 7, 3, 0])
Load Pre-Trained Model#
model = torchvision.models.vgg16(pretrained=True)
model
/usr/local/lib/python3.7/dist-packages/torchvision/models/_utils.py:209: UserWarning: The parameter 'pretrained' is deprecated since 0.13 and will be removed in 0.15, please use 'weights' instead.
f"The parameter '{pretrained_param}' is deprecated since 0.13 and will be removed in 0.15, "
/usr/local/lib/python3.7/dist-packages/torchvision/models/_utils.py:223: UserWarning: Arguments other than a weight enum or `None` for 'weights' are deprecated since 0.13 and will be removed in 0.15. The current behavior is equivalent to passing `weights=VGG16_Weights.IMAGENET1K_V1`. You can also use `weights=VGG16_Weights.DEFAULT` to get the most up-to-date weights.
warnings.warn(msg)
Downloading: "https://download.pytorch.org/models/vgg16-397923af.pth" to /root/.cache/torch/hub/checkpoints/vgg16-397923af.pth
VGG(
(features): Sequential(
(0): Conv2d(3, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(1): ReLU(inplace=True)
(2): Conv2d(64, 64, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(3): ReLU(inplace=True)
(4): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(5): Conv2d(64, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(6): ReLU(inplace=True)
(7): Conv2d(128, 128, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(8): ReLU(inplace=True)
(9): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(10): Conv2d(128, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(11): ReLU(inplace=True)
(12): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(13): ReLU(inplace=True)
(14): Conv2d(256, 256, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(15): ReLU(inplace=True)
(16): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(17): Conv2d(256, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(18): ReLU(inplace=True)
(19): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(20): ReLU(inplace=True)
(21): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(22): ReLU(inplace=True)
(23): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
(24): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(25): ReLU(inplace=True)
(26): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(27): ReLU(inplace=True)
(28): Conv2d(512, 512, kernel_size=(3, 3), stride=(1, 1), padding=(1, 1))
(29): ReLU(inplace=True)
(30): MaxPool2d(kernel_size=2, stride=2, padding=0, dilation=1, ceil_mode=False)
)
(avgpool): AdaptiveAvgPool2d(output_size=(7, 7))
(classifier): Sequential(
(0): Linear(in_features=25088, out_features=4096, bias=True)
(1): ReLU(inplace=True)
(2): Dropout(p=0.5, inplace=False)
(3): Linear(in_features=4096, out_features=4096, bias=True)
(4): ReLU(inplace=True)
(5): Dropout(p=0.5, inplace=False)
(6): Linear(in_features=4096, out_features=1000, bias=True)
)
)
Freezing the Model#
for param in model.parameters():
param.requires_grad = False
Assume we want to fine-tune (train) the last 3 layers:
model.classifier[1].requires_grad = True
model.classifier[3].requires_grad = True
For the last layer, because the number of class labels differs compared to ImageNet, we replace the output layer with your own output layer:
model.classifier[6] = torch.nn.Linear(4096, 10)
Training#
model = model.to(DEVICE)
optimizer = torch.optim.SGD(model.parameters(), momentum=0.9, lr=0.01)
scheduler = torch.optim.lr_scheduler.ReduceLROnPlateau(optimizer,
factor=0.1,
mode='max',
verbose=True)
minibatch_loss_list, train_acc_list, valid_acc_list = train_model(
model=model,
num_epochs=NUM_EPOCHS,
train_loader=train_loader,
valid_loader=valid_loader,
test_loader=test_loader,
optimizer=optimizer,
device=DEVICE,
scheduler=scheduler,
scheduler_on='valid_acc',
logging_interval=100)
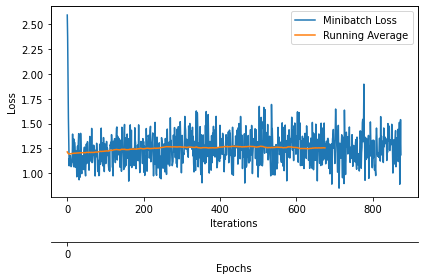
plot_training_loss(minibatch_loss_list=minibatch_loss_list,
num_epochs=NUM_EPOCHS,
iter_per_epoch=len(train_loader),
results_dir=None,
averaging_iterations=200)
plt.show()
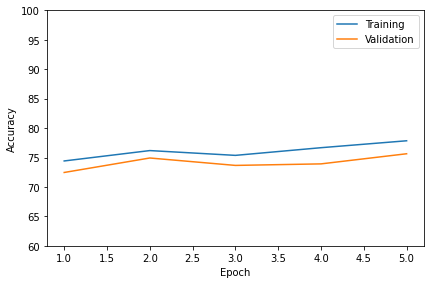
plot_accuracy(train_acc_list=train_acc_list,
valid_acc_list=valid_acc_list,
results_dir=None)
plt.ylim([60, 100])
plt.show()
Epoch: 001/005 | Batch 0000/0175 | Loss: 2.5923
Epoch: 001/005 | Batch 0100/0175 | Loss: 1.2309
Epoch: 001/005 | Train: 74.42% | Validation: 72.46%
Time elapsed: 1.30 min
Epoch: 002/005 | Batch 0000/0175 | Loss: 1.0772
Epoch: 002/005 | Batch 0100/0175 | Loss: 1.0758
Epoch: 002/005 | Train: 76.18% | Validation: 74.92%
Time elapsed: 2.59 min
Epoch: 003/005 | Batch 0000/0175 | Loss: 0.9858
Epoch: 003/005 | Batch 0100/0175 | Loss: 1.5000
Epoch: 003/005 | Train: 75.37% | Validation: 73.66%
Time elapsed: 3.84 min
Epoch: 004/005 | Batch 0000/0175 | Loss: 1.4905
Epoch: 004/005 | Batch 0100/0175 | Loss: 1.3640
Epoch: 004/005 | Train: 76.67% | Validation: 73.92%
Time elapsed: 5.11 min
Epoch: 005/005 | Batch 0000/0175 | Loss: 1.1995
Epoch: 005/005 | Batch 0100/0175 | Loss: 1.2615
Epoch: 005/005 | Train: 77.85% | Validation: 75.64%
Time elapsed: 6.36 min
Total Training Time: 6.36 min
Test accuracy 74.69%
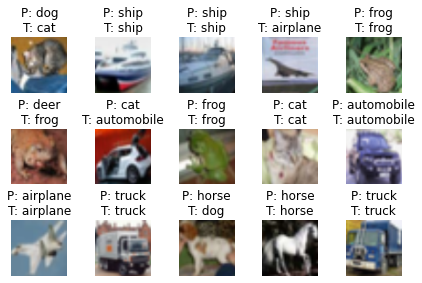
model.cpu()
unnormalizer = UnNormalize((0.485, 0.456, 0.406), (0.229, 0.224, 0.2255))
class_dict = {0: 'airplane',
1: 'automobile',
2: 'bird',
3: 'cat',
4: 'deer',
5: 'dog',
6: 'frog',
7: 'horse',
8: 'ship',
9: 'truck'}
show_examples(model=model, data_loader=test_loader, unnormalizer=unnormalizer, class_dict=class_dict)
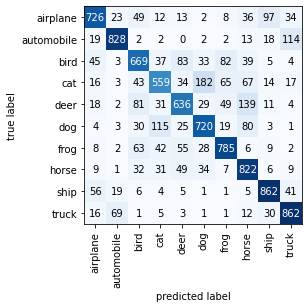
mat = compute_confusion_matrix(model=model, data_loader=test_loader, device=torch.device('cpu'))
plot_confusion_matrix(mat, class_names=class_dict.values())
plt.show()
Acknowledgements
Code adopted from the excellent lectures of Sebastian Raschka